Rio's Homegrown AI Exposed as Merged Model
Discover how Rio de Janeiro's heavily hyped homegrown AI model turned out to be a mere merge of existing open-source technologies rather than a new creation.
- NV Trends
- 9 min read

The global race for artificial intelligence supremacy is no longer just a battle between tech giants in Silicon Valley. Governments, regional municipalities, and independent developers across the globe are rushing to plant their flags in the AI frontier. The promise of “sovereign AI”—models built by and for a specific region, understanding local dialects, culture, and administrative needs—has become the ultimate digital status symbol. Recently, the Brazilian city of Rio de Janeiro made headlines by announcing its very own “homegrown” Large Language Model (LLM), touted as a massive leap forward for local technological innovation and digital independence.
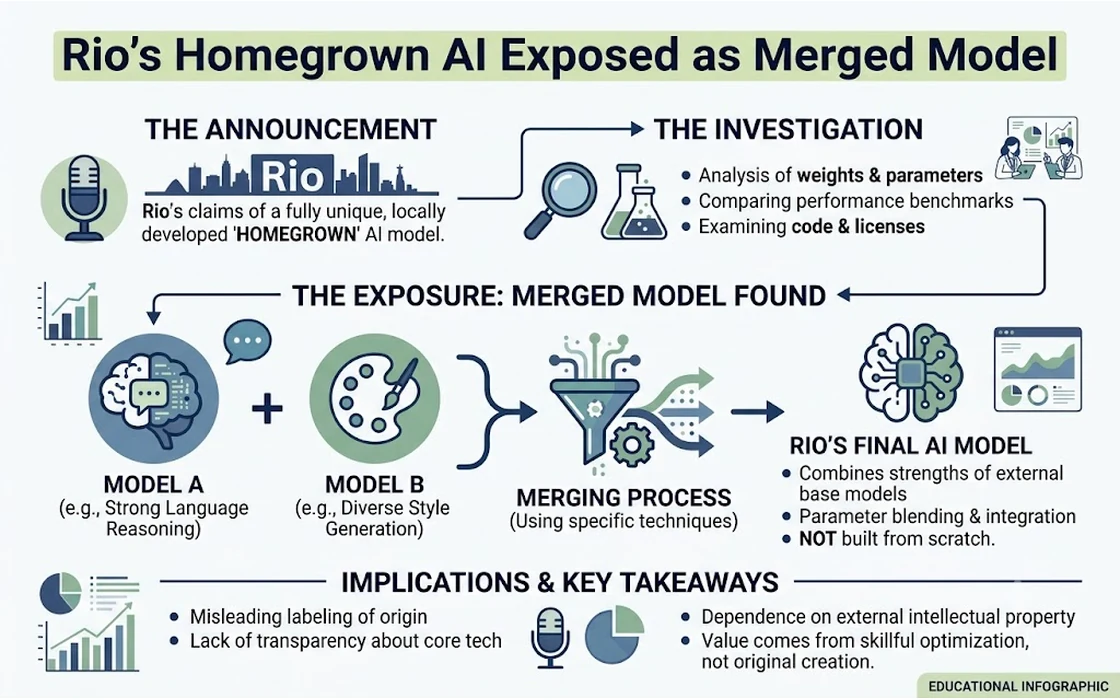
However, the excitement was remarkably short-lived. Within days of the announcement, the global tech community—specifically eagle-eyed developers and researchers on forums like Hacker News—began dissecting the newly released model. What they found wasn’t a groundbreaking, newly trained AI architecture built from the ground up on local data. Instead, digital forensics revealed that Rio’s proud homegrown LLM appears to be little more than a “merge” of existing, open-source AI models developed by other organizations.
This revelation has sparked an intense debate about transparency in the tech industry, the definition of true innovation, and the pervasive culture of “AI washing” where exaggerated claims often outpace actual engineering. As emerging economies, including India, push aggressively to build their own indigenous AI models, the controversy surrounding Rio’s LLM serves as a fascinating case study and a cautionary tale about the perils of tech hype.
The Allure of Sovereign AI
Before dissecting what exactly went wrong with Rio’s announcement, it is crucial to understand why cities and countries are so desperate to have their own AI models in the first place.
Historically, the most capable foundation models—like OpenAI’s GPT-4 or Google’s Gemini—have been developed in the United States. While these models are incredibly powerful, they inherently carry a Western bias. They are trained predominantly on English-language data and Western cultural norms. For a country like India, or a massive municipality like Rio de Janeiro, relying entirely on these foreign models presents several distinct challenges:
- Data Privacy and Security: Governments handle sensitive citizen data. Sending this data to servers hosted by foreign corporations for processing by an LLM raises massive security and sovereignty concerns.
- Cultural and Linguistic Nuance: General models often struggle with the subtle nuances of local languages, regional slang, or specific cultural contexts. A model optimized for American corporate communication might hallucinate or fail when tasked with understanding regional Portuguese dialects or, in the Indian context, translating complex legal documents from Hindi or Tamil.
- Economic Independence: By relying on API calls to foreign tech giants, local governments and businesses continuously leak capital abroad. Building local infrastructure ensures that the financial benefits of AI adoption stay within the domestic economy.
Therefore, when Rio announced a model specifically tailored for its needs, it sounded like a visionary step. It promised to optimize city services, improve public administration, and showcase Brazilian engineering talent to the world.
Unmasking the Model: What is “Model Merging”?
The controversy centers entirely on how the model was created. To understand the backlash from the tech community, one must understand the difference between training a model and merging models.
Training from Scratch: The Crores Problem
Building a foundational LLM from scratch is a monumental undertaking. It involves scraping and curating billions, sometimes trillions, of words (tokens) of data. Once the data is clean, you must run it through massive clusters of Graphics Processing Units (GPUs) for months.
This process, known as pre-training, is prohibitively expensive. Training a state-of-the-art model can easily cost hundreds of crores of rupees just in electricity and compute rental costs. For instance, renting a single high-end Nvidia H100 GPU can cost over Rs. 300 per hour, and training requires thousands of them running simultaneously. Very few organizations on the planet have the capital to do this.
Fine-Tuning: The Middle Ground
A more common approach is taking an existing open-source model (like Meta’s Llama 3 or Mistral) and “fine-tuning” it. You feed the pre-trained model a smaller, highly curated dataset—perhaps thousands of examples of Rio’s municipal codes or Indian legal documents. This tweaks the model’s behavior to specialize in a specific task. Fine-tuning is relatively affordable, often costing just a few thousand to a few lakh rupees, and is a widely respected engineering practice.
Model Merging: The Frankenstein Approach
Model merging, however, is a completely different technique that has recently exploded in popularity on platforms like Hugging Face. Merging does not necessarily involve training the AI on new data. Instead, it involves mathematically combining the “weights” (the internal numbers that dictate an AI’s behavior) of two or more existing, pre-trained models.
Imagine you have two open-source models: Model A is exceptionally good at writing code, and Model B is fantastic at writing creative stories in Portuguese. Using advanced mathematical techniques (with names like SLERP, DARE, or TIES), a developer can literally blend the internal structures of these two models together, hoping the resulting “Frankenstein” model inherits the strengths of both parents.
Crucially, model merging requires almost zero compute power. It can often be done on a standard gaming laptop in a matter of minutes. It is a clever, resourceful trick, but it is fundamentally different from creating an AI model.
How the Tech Community Caught On
You cannot simply slap a new name on an open-source model and expect the global developer community not to notice. When Rio’s model was uploaded, researchers on platforms like Hacker News immediately downloaded the files and began looking under the hood. The telltale signs of a merged model quickly became obvious:
- Identical Architecture and Tokenizers: Every AI model has a “tokenizer”—a specific dictionary it uses to break words into numbers. The tokenizer of the “homegrown” model was a pixel-perfect match for existing open-source models. If a team had genuinely trained a model from scratch for Portuguese, they would have built a custom tokenizer optimized for that language.
- Weight Analysis: Independent researchers wrote scripts to compare the internal weights of the new model against thousands of known open-source models on Hugging Face. The mathematical fingerprints perfectly matched a specific blend of existing, well-known LLMs.
- Peculiar Hallucinations: Merged models often retain the specific quirks or “hallucinations” of their parent models. When prompted with highly specific edge-case questions, the Rio model gave the exact same flawed responses as the models it was allegedly built from.
The verdict was swift and unforgiving. The developers hadn’t built an AI; they had downloaded free tools, ran a simple mathematical blending script, and packaged it in a shiny press release claiming a major technological breakthrough.
The Ethics of “AI Washing”
The core issue here is not the act of merging models. Model merging is a legitimate, highly useful part of the modern open-source AI ecosystem. Many developers use merging to create incredibly capable, specialized tools without spending millions of dollars. The offense lies entirely in the misrepresentation.
When a government or a corporation claims they have developed a “homegrown” foundational model, it implies deep technical expertise, massive infrastructural investment, and original intellectual property. It signals to investors, citizens, and the global market that they possess the rare capability to engineer AI at the lowest levels.
Passing off a merged open-source model as a scratch-built innovation is what the industry refers to as “AI washing”—using the hype surrounding artificial intelligence to make a product or initiative seem far more advanced than it actually is.
- For taxpayers, it raises questions about where the funding for this “massive project” actually went, considering the end product could be generated for free on a laptop.
- For the local tech community, it is demoralizing. Genuinely hard-working researchers who are painstakingly building real datasets and fine-tuning models are overshadowed by a PR stunt.
- For the global ecosystem, it adds noise and erodes trust. When actual breakthroughs happen, the public may be too cynical to believe them.
Lessons for the Indian Tech Ecosystem
This controversy in Brazil holds immense relevance for India. India is currently experiencing an absolute boom in AI development. Startups are raising hundreds of crores, and the government is actively pushing initiatives like the IndiaAI Mission. We are seeing a flurry of announcements for “Bharat-centric” LLMs designed to speak Hindi, Tamil, Telugu, and Marathi.
As we build our own sovereign AI capabilities, the Indian tech ecosystem must internalize the lessons from Rio’s misstep:
1. Embrace Open Source, But Be Transparent
There is zero shame in standing on the shoulders of giants. Building upon open-source models like Llama 3 or Qwen is the smartest, most cost-effective way for Indian startups to deliver value quickly. However, companies must be radically transparent about their foundation. Announcing, “We have heavily fine-tuned Llama 3 on 500 gigabytes of verified Hindi legal texts,” is a massive, respected achievement. Claiming “We built a new Hindi AI from scratch” when you merely fine-tuned someone else’s model is a recipe for a PR disaster. Indian developers are world-class; we do not need to hide our methods behind marketing speak.
2. Focus on Data, Not Just Compute
The Rio debacle shows that you cannot fake a foundational model. If India wants true sovereign AI, the focus must relentlessly remain on data collection. The biggest moat for any Indian AI company won’t be the algorithm—those are largely open source—it will be high-quality, culturally accurate, legally unencumbered local datasets. Curating a massive, clean dataset of Indian languages is harder and more valuable than running a model merge script.
3. Educate the Decision Makers
Often, “AI washing” happens not because the engineers are malicious, but because politicians, bureaucrats, or marketing teams demand a “world-first” announcement without understanding the technology. The tech community in India must actively educate policymakers and investors on the realities of AI development. Understanding the difference between a wrapper, a fine-tuned model, a merged model, and a foundation model is crucial for allocating funding effectively and setting realistic public expectations.
4. Celebrate Genuine Engineering
We must cultivate an environment where genuine, incremental engineering is celebrated over flashy overnight announcements. Building a robust evaluation framework for Indic languages, creating an efficient tokenizer for Dravidian scripts, or optimizing a model to run on low-end smartphones—these are the real, unglamorous technical victories that will secure India’s digital future, not PR-driven vaporware.
Conclusion
The saga of Rio de Janeiro’s “homegrown” LLM is a perfectly timed reality check for the global artificial intelligence industry. As AI continues to dominate headlines and attract massive investment, the temptation to exaggerate technological capabilities will only grow stronger. The quick unmasking of the merged model by the open-source community proves that in the modern digital age, technical obfuscation rarely survives public scrutiny.
For regions like India, aggressively charting their own course in the AI landscape, the takeaway is clear: true technological sovereignty cannot be downloaded, merged, and rebranded. It requires the hard, expensive, and time-consuming work of building real infrastructure, curating authentic local data, and fostering a culture of absolute transparency. Open-source technology is a powerful accelerant, a tool that democratizes access to the future, but it must be used with honesty. In the race for AI supremacy, genuine innovation will always outlast a good press release.