The Data Privacy U-Turn: Why the US Census Banned Noise Infusion
A deep dive into the US Census Bureau's ban on noise infusion, its impact on data accuracy, and the lessons for India's upcoming 2027 digital census.
- NV Trends
- 8 min read

In the world of big data, there has always been a delicate, almost impossible balancing act between protecting the individual and serving the collective. For years, the gold standard for this balance was a sophisticated mathematical technique known as “differential privacy” or, more colloquially, noise infusion. By intentionally adding random “noise” to datasets, government agencies aimed to hide individual identities while preserving the overall statistical truth. It was hailed as the future of secure governance—until now.
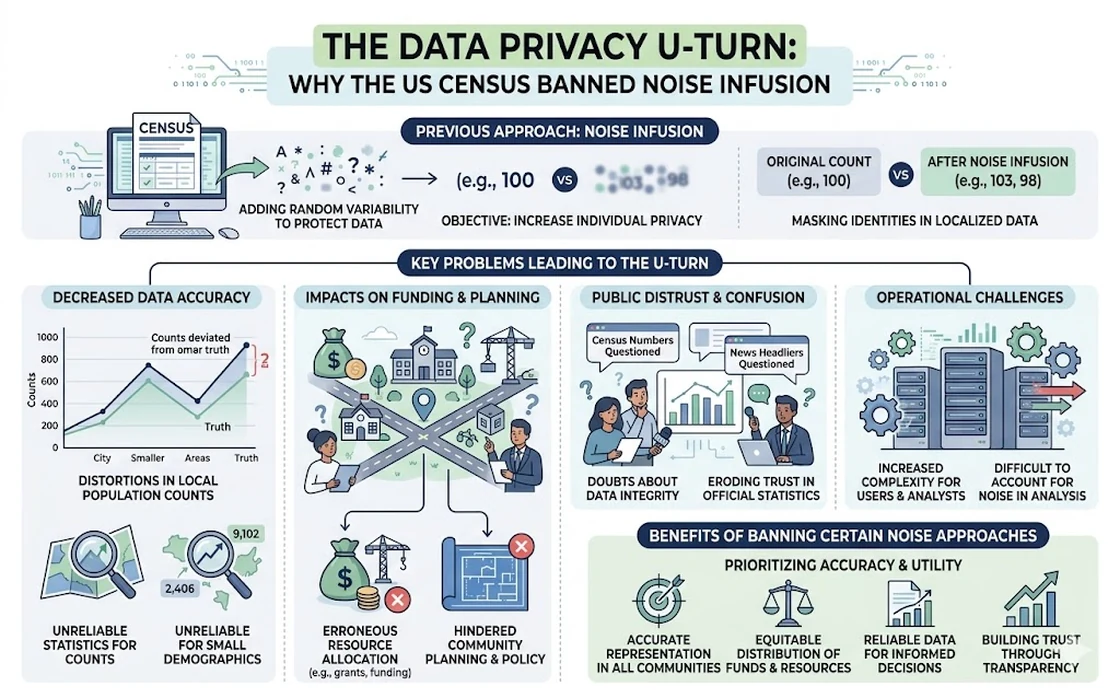
In a move that has sent shockwaves through the global data science community and reached the front pages of platforms like Hacker News, the United States Department of Commerce recently issued an administrative order banning the use of noise infusion in statistical products published by the Census Bureau. This decision marks a significant retreat from a technology that was only recently mandated as the “only way” to protect data in the 2020s. For a general reader, this might sound like a technical bureaucratic shift, but for anyone living in a data-driven society like India, the implications are profound.
As India prepares for its first-ever fully digital census in 2027, the US “U-turn” serves as a critical case study. If the world’s most advanced statistical agency found noise infusion to be more of a hindrance than a help, what does it mean for the privacy of 1.4 billion people? Understanding why “noise” was silenced requires us to look deep into the machinery of modern privacy and the high-stakes game of resource allocation.
What Exactly is Noise Infusion?
To understand the ban, we must first understand the problem it was trying to solve. In our digital age, “anonymizing” data by simply removing names and addresses is no longer enough. Data scientists have discovered “database reconstruction attacks,” where powerful algorithms can cross-reference “anonymized” public records with other datasets (like social media or commercial databases) to re-identify individuals with startling accuracy.
Differential Privacy (DP), or noise infusion, was the mathematical shield against this. Imagine a village of 100 people where you want to report the average income. If you report the exact number, and someone knows the income of 99 people, they can easily calculate the 100th person’s income. Noise infusion solves this by adding a small, random amount to the total—say, changing a total of Rs. 1,00,000 to Rs. 1,00,050.
The goal is to ensure that the “noise” is large enough to hide the individual but small enough that the final average remains useful for policy decisions. In the 2020 US Census, this was implemented at a massive scale, injecting “fuzziness” into every block-level data point across the country.
The Clash: Privacy vs. Statistical Accuracy
The theory behind noise infusion is elegant, but the execution in the 2020 US Census faced immediate and fierce backlash. While privacy advocates cheered, the people who actually use census data—demographers, city planners, and social scientists—found themselves looking at data that simply didn’t make sense.
In some small towns, the “noise” was so significant that the census reported more households than people, or reported children living in blocks where there were no adults. For a local government trying to decide where to build a new primary school or how to allocate a budget of Rs. 50 crore for infrastructure, this “fuzzed” data was worse than useless; it was misleading.
The “Privacy Loss Budget”
In differential privacy, there is a parameter called “epsilon” ($\epsilon$), which represents the Privacy Loss Budget. A lower epsilon means more noise and better privacy, but lower accuracy. A higher epsilon means less noise and better accuracy, but higher privacy risk.
The US Census Bureau struggled to find the “sweet spot.” If they made the data accurate enough for local planning, the privacy protection became too thin. If they made the privacy robust, the data became “noisy” and “broken” for small-area statistics. This fundamental tension eventually led to the 2026 ban.
Why the US Banned the Noise
The administrative order from the Department of Commerce reflects a growing realization: the “utility” of data is a public good that cannot be sacrificed entirely at the altar of mathematical privacy. There were three primary drivers for this ban:
- Distrust in Local Governance: Local officials argued they couldn’t perform their duties (like redistricting or budget planning) with data that didn’t reflect their reality on the ground.
- The Rise of “Coarsening”: The ban doesn’t mean the Census Bureau is giving up on privacy. Instead, it is returning to older, more “human-readable” methods like aggregation and suppression.
- Legal Challenges: Several states sued the Bureau, arguing that the US Constitution and the Census Act require “actual enumeration”—meaning real counts, not mathematically altered ones.
By banning noise infusion, the US government is signaling that it prefers data that is slightly less granular but 100% “real” over data that is granular but “fictionalized” by algorithms.
The Alternative: Coarsening and Suppression
With noise infusion off the table, the Census Bureau and the Bureau of Economic Analysis (BEA) are shifting back to traditional methods of Disclosure Avoidance. These include:
- Aggregation: Instead of reporting data for a tiny neighborhood (a census block), the data is combined into a larger ward or district. This naturally hides individuals by “burying” them in a larger crowd.
- Rounding: Numbers are rounded to the nearest 5, 10, or 100. If a village has 13 farmers, the report might say “15” or “10-15.”
- Suppression: If a data point is so specific that it might reveal an individual (e.g., there is only one person of a certain age and occupation in a district), that data point is simply not published.
For researchers, these methods are often preferred because, while they provide less detail, the numbers that are provided are known to be accurate. In a country like India, where local planning is often done at the “Gram Panchayat” level, this distinction is vital.
Implications for India’s 2027 Digital Census
India is currently standing at a digital crossroads. The 2021 Census was delayed, and it has now been reimagined as the 2027 Digital Census. This will be the largest digital exercise in human history, collecting data from over 1.4 billion people via mobile apps and self-enumeration portals.
The US ban on noise infusion is a timely warning for India’s Office of the Registrar General & Census Commissioner (ORGI). Here is why this matters for the Indian reader:
1. The DPDPA 2023 Context
India recently passed the Digital Personal Data Protection Act (DPDPA), 2023. While the Census is exempted from some consent requirements under the “Legitimate Use” clause, the government still has a massive responsibility to protect this data. The debate over whether to use Differential Privacy in the 2027 Census is already active in policy circles.
2. Allocation of “Rupees” (Rs.)
In India, the census is not just about counting people; it is the “mother of all databases” for financial allocation. The Finance Commission uses census data to decide how much of the central tax revenue (GST, etc.) goes to each state. If “noise” were to artificially lower the population count of a specific district in Bihar or Tamil Nadu, that district could lose out on hundreds of crores of rupees in development funds.
3. The Aadhaar Factor
India already has experience with large-scale data privacy via the Aadhaar system. The lessons from Aadhaar—where “security by design” is prioritized—will likely influence the Census. However, unlike Aadhaar, which is an identity system, the Census is a statistical system. The US experience shows that the privacy tools used for identity (like encryption) are different from the tools used for statistics (like noise infusion).
A Case Study: The Rs. 1000 Crore Dilemma
To see the impact of this “noise” in real terms, consider a hypothetical central government scheme for “Rural Healthcare Infrastructure.” The government decides to allocate Rs. 1000 crore based on the number of elderly citizens living in “High-Need” districts.
- Scenario A (With Noise Infusion): To protect the privacy of elderly citizens in small villages, the system adds “noise.” A district with 5,000 elderly citizens might be reported as having 4,800. The district loses its “High-Need” status and misses out on a Rs. 50 crore hospital grant.
- Scenario B (With Coarsening/Suppression): The system reports data at the district level only, not the village level. The count is exactly 5,000. The privacy of the individual village is protected by the “crowd” of the district, and the funding is allocated accurately.
This is the core reason why the US is moving back to coarsening. In a world of limited resources, “accuracy” is often more important for social justice than “perfect mathematical privacy.”
The Future of Statistical Privacy
The ban on noise infusion doesn’t mean the end of privacy-enhancing technologies (PETs). Rather, it signals a maturation of the field. We are moving away from “one-size-fits-all” mathematical models toward a more nuanced, “context-aware” approach to data protection.
In the future, we might see “Hybrid Models” where:
- Public Data is protected by traditional coarsening (safe for local planning).
- Microdata (anonymized records for researchers) is protected by advanced Differential Privacy.
- Sensitive Data is processed via “Secure Multi-Party Computation,” where the data is never actually “seen” by the researcher, only the results of their queries.
Conclusion
The US Census Bureau’s decision to ban noise infusion is a rare instance of a government agency admitting that a cutting-edge technology was not yet ready for the “real world” of high-stakes governance. It is a victory for the “utility” of data and a reminder that statistics serve a human purpose: to help us build better cities, better hospitals, and more equitable societies.
For India, as we embark on the 2027 Digital Census, the lesson is clear. We must be wary of “mathematical silver bullets.” Our privacy framework, anchored by the DPDPA 2023, must prioritize the safety of the individual, but it cannot do so by making our national data “noisy” or unreliable.
When it comes to the census, every person counts—and they must be counted accurately. Whether it is the distribution of Rs. 5 or Rs. 5,000 crore, the foundation of a fair democracy is built on data we can trust. The noise has been silenced, and in its place, we find a renewed commitment to the simple, powerful truth of the headcount.